Immer wieder taucht die Idee einer llms.txt auf – einer Datei, die LLMs hilft, die wichtigsten Informationen einer gesamten Webseite schnell und effizient zu analysieren. Aktuell ist sie jedoch kein offizieller Standard und wird von den grossen KI-Plattformen wie ChatGPT, Perplexity und Claude nicht unterstützt.
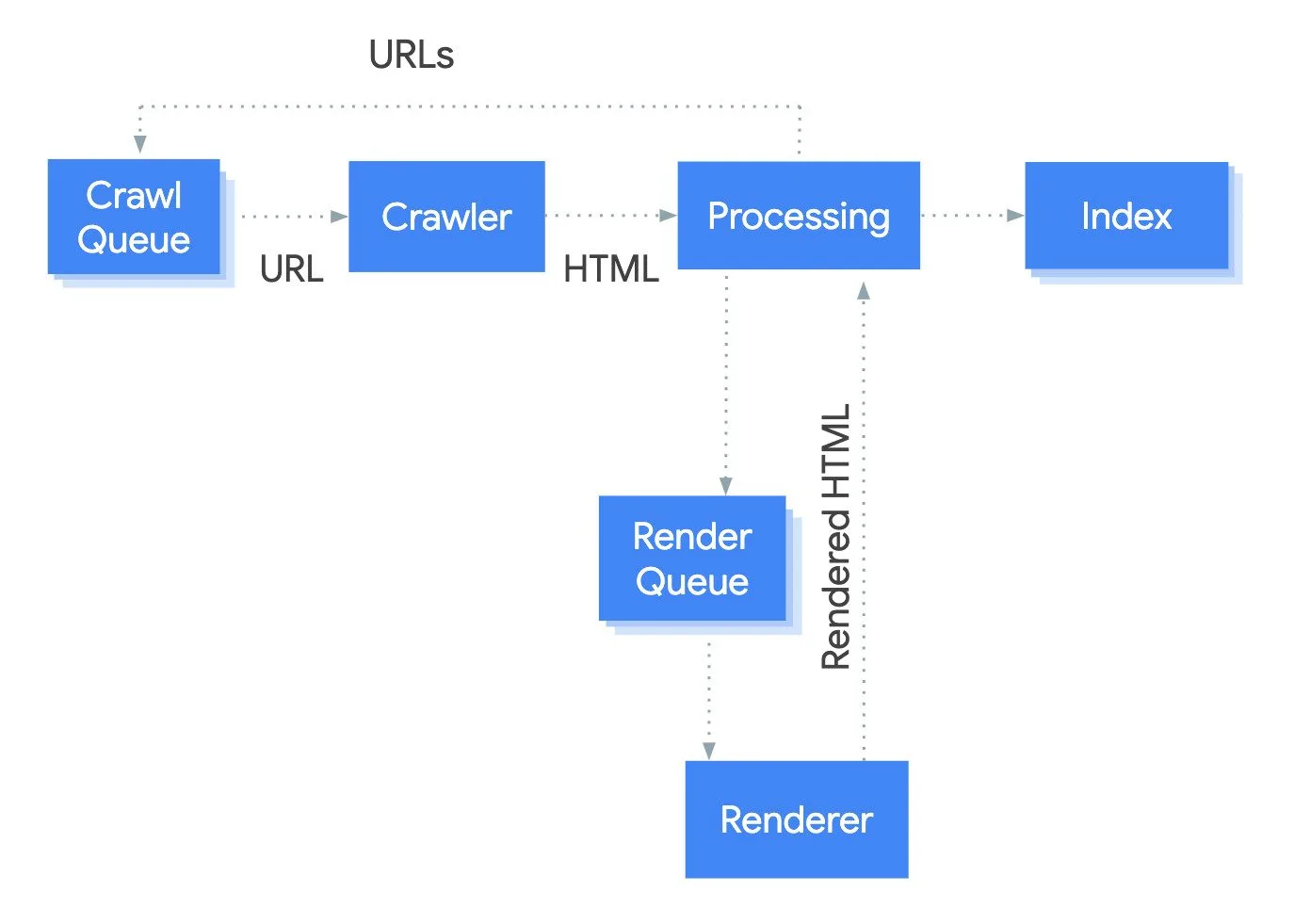
Die robots.txt-Datei, Sitemaps sowie eine gute interne Verlinkung sind und bleiben derzeit die bewährtesten Methoden, um nicht nur Suchmaschinen-Crawlern, sondern auch KI-Bots zielgerichtet und effizient zu den relevanten Inhalten deiner Webseite zu führen.
Wer Sichtbarkeit in LLMs anstrebt, sollte zudem sicherstellen, dass relevante KI-Crawler in Firewalls und Content Delivery Networks (CDNs) nicht versehentlich gesperrt sind. Einige Firewalls und CDN-Anbieter wie Cloudflare schliessen KI-Bots standardmässig vom Crawling aus. Eventuell musst du hier ein Whitelisting für relevante KI-Bots vornehmen oder das Crawling durch KI-Crawler aktiv zulassen.
Wenn bestimmte LLMs deine Inhalte nicht für Trainingszwecke verwenden sollen, kannst du die entsprechenden Bots gezielt blockieren. Das reduziert allerdings auch die Sichtbarkeit in KI-gestützten Suchmaschinen.
Solange es keine offiziellen neuen Protokolle oder Standards gibt, gilt daher: Beobachte die Entwicklung, überprüfe Logfiles, Firewall- und CDN-Einstellungen und nutze die robots.txt, Sitemaps sowie interne Verlinkungen strategisch. Transparenz und Kontrolle bleiben die Basis.