The idea of an llms.txt file keeps cropping up – a file that helps LLMs analyse the most important information on an entire website quickly and efficiently. However, it is not currently an official standard and is not supported by major AI platforms such as ChatGPT, Perplexity and Claude.
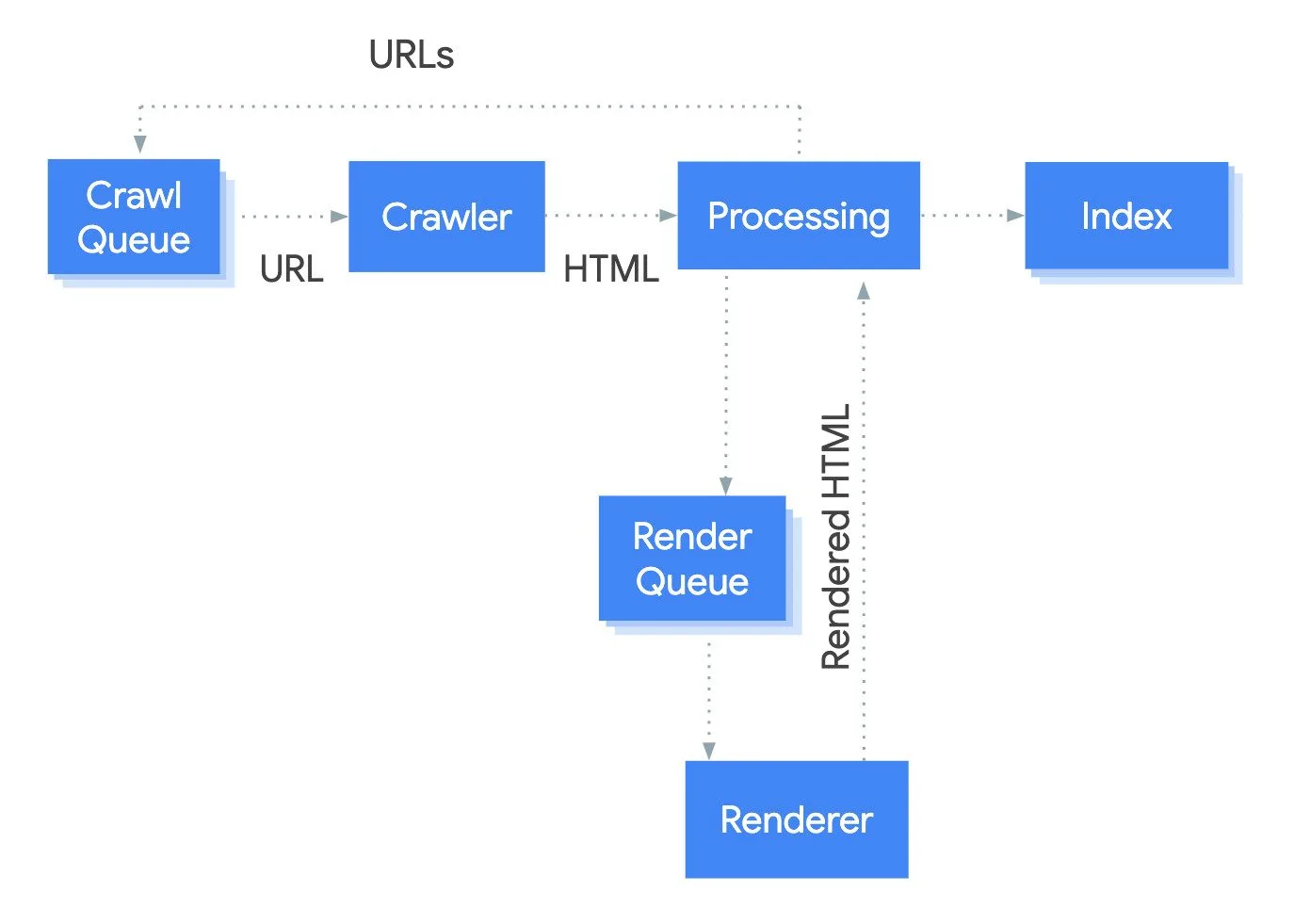
The robots.txt file, sitemaps and good internal linking are and remain the most proven methods for guiding search engine crawlers and AI bots alike to the relevant content on your website in a targeted and efficient manner.
If you want to be visible in LLMs, you should also make sure that relevant AI crawlers are not accidentally blocked by firewalls and content delivery networks (CDNs). Some firewalls and CDN providers, such as Cloudflare, exclude AI bots from crawling by default. You may need to whitelist relevant AI bots or actively allow crawling by AI crawlers. If you do not want certain LLMs to use your content for training purposes, you can block those bots specifically. However, this also reduces visibility in AI-powered search engines.
As long as there are no official new protocols or standards, the following applies: monitor developments, check log files, firewall and CDN settings, and use robots.txt, sitemaps and internal links strategically. Transparency and control remain the basis.